Lumiere,谷歌研究院开发的基于空间时间的文本到视频扩散模型。采用了创新的空间时间U-Net架构,能够一次性生成整个视频的时间长度,确保了生成视频的连贯性和逼真度。
大家好~这里是小编!本期【放心AI网-核心AI】带你解锁超实用AI神器,精选全网热门工具,助你一键开启智能新体验!
Lumiere是谷歌研究院团队开发的基于空间时间的文本到视频扩散模型。Lumiere采用了创新的空间时间U-Net架构,该架构通过模型中的单次传递一次性生成视频的整个时间,不同于其他模型那样逐帧合成视频。确保了生成视频的连贯性和逼真度,Lumiere可以轻松促进广泛的内容创建任务和视频编辑应用程序,包括图像到视频、视频修复和风格化生成。

文本到视频的扩散模型: Lumiere能够根据文本提示生成视频,实现了从文本描述到视频内容的直接转换。
图像到视频:该模型通过对第一帧进行调节,将静止图像平滑地转换为视频。
空间时间U-Net架构: 与其他需要逐步合成视频的模型不同,Lumiere能够一次性完成整个视频的制作。这种独特的架构允许Lumiere一次性生成整个视频的时间长度,不同于其他模型那样逐帧合成视频。
全局时间一致性: 由于其架构的特点,Lumiere更容易实现视频内容的全局时间一致性,确保视频的连贯性和逼真度。
多尺度空间时间处理: Lumiere通过在多个空间时间尺度上处理视频来学习直接生成视频,这是一种先进的方法。
风格化视频生成: 使用单个参考图像,Lumiere可以按照目标风格生成视频,这种能力在其他视频生成模型中较为罕见。
广泛的内容创作和视频编辑应用: Lumiere支持多种内容创作任务和视频编辑应用,如图像到视频、视频修补和风格化生成。
视频样式化编辑: 使用文本基础的图像编辑方法,Lumiere可以对视频进行一致性的样式编辑。
影像合成能力: 当图像的一部分保持静止而另一部分呈现运动时,可以实现局部运动效果,从而为静止图像增添迷人的美感。
视频修复功能: Lumiere 可以根据文本提示对现有视频的任意遮罩区域进行动画处理。这为视频编辑、对象插入和/或删除提供了有趣的可能性。

尽管取得了这些进步,但Lumiere在需要在不同场景和镜头之间转换的视频方面仍然受到限制。这种能力差距为未来的扩散模型研究提供了重要方向。
今天的AI工具安利就到这里啦!小伙伴们还想看哪些神器?快留言告诉小编,放心AI网-核心AI下期继续带你挖宝!
需要网络免费
资讯AI更多
资讯AI 更多

甲骨文推出新AI智能体和生成式AI功能,助力销售团队提升客户互动
更新时间:2025-04-30
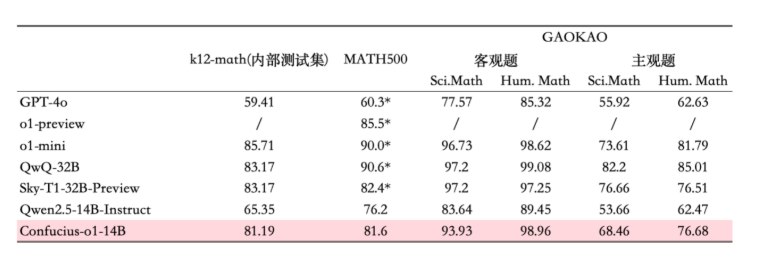
网易有道推出“子曰-o1”推理模型,教育领域迎来新变革
更新时间:2025-04-30

豆包上线深度推理模式:AI逻辑链条可视化,问答搜索新突破
更新时间:2025-04-17

当AI制药不再讲故事
更新时间:2025-04-30

成都华微:AI算力高达16Tops的人工智能芯片已小批量试用
更新时间:2025-04-30

谷歌全新升级Gemini2.0FlashThinking,长上下文处理能力再创新高
更新时间:2025-04-30

网易有道子曰-o1推理模型正式开源发布专为消费级显卡设计
更新时间:2025-04-30

谷歌推出实时AI视频功能Gemini:手机摄像头瞬间解读画面内容。
更新时间:2025-04-09

苹果重组AI高管团队,Siri升级延后至未来五年规划——AI高管团队重组影响Siri升级计划,预计推迟至2026年。
更新时间:2025-04-09

“星际迷航”黑科技照进现实!AI超声技术斩获百万美元大奖,你的心脏健康要被重新定义了!
更新时间:2025-04-16



















