LLaMa模型,github下载,Meta(Facebook)开放和高效的基础语言模型
放心AI网·扩展AI栏目来啦!小编带你挖掘那些小众但超好用的AI神器,错过就亏大啦~
LLaMa模型官网,github下载,Meta(Facebook)开放和高效的基础语言模型
在2月25日,Meta官网发布了一款名为LLaMA(LargeLanguageModelMetaAI)的新型大型语言模型。根据参数规模,Meta提供了70亿、130亿、330亿和650亿四种不同参数规模的LLaMA模型,并使用20种语言进行了训练。与现有最佳的大型语言模型相比,LLaMA模型在性能上具有竞争力。
LLaMa模型官网:https://www.llama.com/
github项目地址: https://github.com/facebookresearch/llama
论文地址:https://arxiv.org/abs/2302.13971
中文LLaMA&Alpaca大语言模型+本地CPU/GPU训练部署(ChineseLLaMA&AlpacaLLMs):
https://github.com/ymcui/Chinese-LLaMA-Alpaca
LLaMA(LargeLanguageModelMetaAI),由MetaAI发布的一个开放且高效的大型基础语言模型,共有7B、13B、33B、65B(650亿)四种版本。其数据集来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现,整个训练数据集在token化之后大约包含1.4T的token。
关于模型性能,LLaMA的性能非常优异:具有130亿参数的LLaMA模型「在大多数基准上」可以胜过GPT-3(参数量达1750亿),而且可以在单块V100GPU上运行;而最大的650亿参数的LLaMA模型可以媲美谷歌的Chinchilla-70B和PaLM-540B。
关于训练集,其来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现。整个训练数据集在token化之后大约包含1.4T的token。其中,LLaMA-65B和LLaMA-33B是在1.4万亿个token上训练的,而最小的模型LLaMA-7B是在1万亿个token上训练的。
总体而言,LLaMA模型表现出色:拥有130亿参数的LLaMA模型在大多数基准测试中胜过了参数规模为1750亿的GPT-3,并且可以在单块V100GPU上运行;而拥有650亿参数的LLaMA模型在性能上与谷歌的Chinchilla-70B和PaLM-540B相媲美。
Meta的首席执行官马克·扎克伯格表示,LLaMA模型旨在帮助研究人员在生成文本、对话、总结书面材料、证明数学定理或预测蛋白质结构等更复杂的任务上取得进展,具有广阔的前景。
LLaMA模型相比Chinchilla、PaLM、GPT-3和ChatGPT等模型具有哪些优势和特点呢?
目前,Meta已经将相关论文上传至arXiv。
类似其他大型语言模型,LLaMA模型也存在一些问题,例如可能会产生偏见、有毒或虚假内容。Meta通过开源吸引更多研究人员的参与,以解决这些问题。
为了确保完整性和防止滥用,Meta将向非商业研究机构开放LLaMA的开源访问权限,并根据具体情况授予学术研究人员访问权限。这些权限将逐步授予**、民间组织、学术界以及全球工业研究实验室的组织。
值得注意的是,LLaMA并非仅仅是一个聊天机器人,而是一种研究工具,可能用于解决与AI语言模型相关的问题。它是一套”更小、性能更好”的模型,并与谷歌的LaMDA和OpenAI的GPT模型不同,LLaMA是基于公开资料进行训练的。LLaMA并非针对特定任务进行微调的模型,而是适用于许多不同任务的通用模型。
LLaMA模型将向整个AI研究社区开源,授予大学、非**组织和工业实验室访问权限。通过这种开源的方式,有助于解决大型语言模型中不可避免的偏见、有毒性和虚假内容的风险。
同时,小型模型通过使用更多的数据进行训练,可以超越大型模型,例如LLaMA-13B在大多数基准测试中优于1750亿参数的GPT-3;而LLaMA-65B的性能与更大规模的Chinchilla-70B和PaLM-540B相媲美。
以ChatGPT、GPT-4等为代表的大语言模型(LargeLanguageModel,LLM)掀起了新一轮自然语言处理领域的研究浪潮,展现出了类通用人工智能(AGI)的能力,受到业界广泛关注。然而,由于大语言模型的训练和部署都极为昂贵,为构建透明且开放的学术研究造成了一定的阻碍。
中文LLaMA模型
为了促进大模型在中文NLP社区的开放研究,本项目开源了中文LLaMA模型和指令精调的Alpaca大模型。这些模型在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,中文Alpaca模型进一步使用了中文指令数据进行精调,显著提升了模型对指令的理解和执行能力。详细内容请参考技术报告(Cui,Yang,andYao,2023)。
本项目主要内容:
需要网络免费
资讯AI更多
资讯AI 更多

西班牙拟立法打击AI生成的色情图像,保护未成年人隐私
更新时间:2025-03-26

吉卜力风格AI图刷屏,OpenAI测试GPT - 4o生图模型水印
更新时间:2025-04-08

快手发布财报:Allin视频大模型可灵AI商业化首战告捷
更新时间:2025-03-27
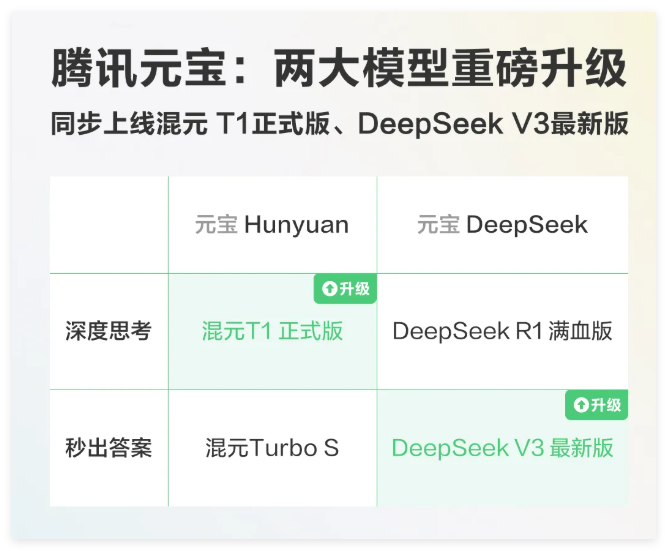
腾讯混元T1正式版和DeepSeekV3-0324上线元宝
更新时间:2025-03-29

互联网医疗AI布局提速,服务质量升级把握新契机
更新时间:2025-04-01

德克萨斯州Alpha学校应用AI辅导系统后,学生成绩提升至全美顶尖行列。
更新时间:2025-04-08
IDC发布报告:全球与中国AI市场投资规模将大幅增长
更新时间:2025-04-08

【重磅来袭】小米MIJIA智能音频眼镜2全新上市,轻薄设计实现录音控车功能,科技升级引领潮流!
更新时间:2025-04-08

全球首款智能体重管理助手“减单”诞生,开启健康新纪元。
更新时间:2025-04-09

Midjourney核心开发者theseriousadult离职,投身Cursor研发AI编程智能体
更新时间:2025-04-10





















