百度文心大模型官网,ai作画网站,写作,ai绘画,论文,文生图,写歌
放心AI网·扩展AI栏目来啦!小编带你挖掘那些小众但超好用的AI神器,错过就亏大啦~
百度文心大模型官网,ai作画网站,写作,ai绘画,论文,文生图,写歌
6月20日消息,据内部人士透露,百度文心大模型3.5版本已经开始内测,用户可以使用这一版本的功能。早在5月末的中关村论坛上,百度的创始人、董事长兼CEO李彦宏透露,百度大模型产品”文心一言”的”母本”即将推出3.5版本,这距离上一个版本发布还不到一个月的时间。
百度文心大模型官网:https://wenxin.baidu.com/
面向语言理解、语言生成等NLP场景,具备超强语言理解能力以及对话生成、文学创作等能力。创新性地将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的新知识,实现模型效果不断进化。文心·NLP大模
ERNIE3.0Zeus
基于知识增强的千亿模型,在各类真实场景的生成准确性、流畅性、相关性上全面领先业界其他大模型。
ERNIE3.0
刷新54个中文NLP任务基准,并登顶SuperGLUE全球榜首,同时具备超强语言理解能力以及写小说、歌词、诗歌、对联等文学创作能力。
鹏城-百度·文心
全球首个知识增强超大模型,参数规模2600亿,在60多项典型任务中取得了世界领先效果,在各类AI应用场景中均具备极强的泛化能力。
ERNIE3.0-Tiny
首个基于多任务知识注入的下游无关蒸馏模型。在兼顾模型的效果与性能同时,表现出了出色的泛化性优势。在16个英文公开数据集以及11个中文数据集上取得效果SOTA。
ERNIE-Health
医疗领域模型,通过学习海量的医疗数据,精准地掌握了专业的医学知识,并登顶权威中文医疗信息处理挑战榜CBLUE榜首。
ERNIE-Finance
金融领域模型,从海量金融数据中学习了金融领域专业知识,在多个金融领域任务上大幅优于通用模型。
PLATO
全球首个超百亿参数规模的中英文对话预训练模型,对话效果全球领先,让机器可以像人一样进行有逻辑、有内容的流畅对话。
ERNIE-UIE
开放域信息抽取模型,统一支持了10+种信息抽取任务,在7个公开数据集上效果领先,同时具有卓越的零样本少样本抽取能力。
ERNIE-Search
搜索大模型,以领先搜索能力登顶段落排序榜单MS-MARCO。
ERNIE-M
跨语言模型,通过大规模的单语语料和双语语料捕捉多语言知识,可以同时建模96种语言,适用于各项多语言任务,跨语言任务,小语种任务。
ERNIE-Code
首个多自然语言多编程语言代码大模型,支持100多种自然语言和15种编程语言。采用多语言多任务联合训练,在代码补全、代码搜索、代码摘要、代码修复等任务上取得领先效果。
ERNIE-Sage
图语义神经网络模型,融合语义与图结构提升文本图理解能力。
首个基于多任务知识注入的下游无关蒸馏模型。在兼顾模型的效果与性能同时,表现出了出色的泛化性优势。在16个英文公开数据集以及11个中文数据集上取得效果SOTA。
文心·CV大模型
基于领先的视觉技术,利用海量的图像、视频等数据,为企业和开发者提供强大的视觉基础模型,以及一整套视觉任务定制与应用能力
文心·CV大模型
VIMER-CAE
视觉自监督预训练模型,创新性地提出“在隐含的编码表征空间完成掩码预测任务”的预训练框架,在图像分类、目标检测、语义分割等经典下游任务上达到SOTA结果
VIMER-UFO
视觉多任务统一大模型,可抽取轻量级小模型,兼顾大模型效果和小模型推理性能,单模型覆盖20+CV基础任务,在28个公开测试集上效果SOTA
VIMER-StrucTexT
端到端文档OCR表征学习预训练模型,创新性地提出“单模态图像输入、多模态表征学习”预训练框架,在5项文档图像理解任务上刷新SOTA结果
VIMER-UMS
行业首个统一视觉单模态与多源图文模态表征的商品多模态预训练模型,在多个商品下游视觉检索、跨模态检索任务上达到SOTA
工具与平台
零门槛AI开发平台EasyDL
面向AI应用开发者,零代码实现基于文心大模型定制您专属的AI模型,可一键发起模型训练、模型效果校验,支持多端部署。
全功能AI开发平台BML
面向AI算法开发者,提供集成化的开发环境,支持基于文心大模型进行高效定制开发,一站式完成AI模型全生命周期管理。
文心·跨模态大模型
基于知识增强的跨模态语义理解关键技术,可实现跨模态检索、图文生成、图片文档的信息抽取等应用的快速搭建,落实产业智能化转型的AI助力
文心·跨模态大模型
ERNIE-ViLG2.0
首个知识增强跨模态生成大模型,基于混合降噪专家模型框架,在文本生成图像任务刷新世界最好效果
ERNIE-ViL
首个知识增强跨模态大模型,将场景图的结构化知识融入预训练,在视觉问答、跨模态检索等5个典型跨模态任务上刷新世界最好效果。
ERNIE-Layout
跨模态文档理解模型,首次将布局知识增强技术融入跨模态文档预训练,在4项文档理解任务上刷新世界最好效果,登顶DocVQA榜首。
ERNIE-SAT
文心跨模态大模型,由语音和语言跨模态联合预训练,显著增强语音语言跨模态任务效果。
ERNIE-GeoL
“地理-语言”预训练模型,学习地理与语言间的关联,百度地图应用效果显著
文心·生物计算大模型
融合自监督和多任务学习,并将生物领域研究对象的特性融入模型。构建面向化合物分子、蛋白分子的生物计算领域预训练模型,赋能生物医药行业。
文心·行业大模型
文心大模型与各行业企业联手,在通用大模型的基础上学习行业特色数据与知识,建设行业AI基础设施
最新的文心大模型3.5版本具备了怎样的实力呢?通过在公开测试集上进行的基础模型少样本(Few-Shot)评测,文心大模型3.5(ERNIE3.5)在多个测试集上的得分已经超过了ChatGPT。这表明百度的文心大模型3.5版本在处理少样本情况下的表现非常出色。相较于之前的版本,这一版本的性能有了明显的提升。用户可以期待在使用文心大模型3.5版本时,获得更加准确和高质量的结果。
百度一直致力于推动自然语言处理领域的发展,文心大模型的不断优化和更新是其努力的体现。通过内测和测试,百度能够不断改进文心大模型的性能,为用户提供更好的体验。随着百度文心大模型3.5版本的发布,相信用户在使用过程中将能够感受到其强大的功能和效果。百度将继续推动文心大模型的发展,为用户提供更加优秀的自然语言处理能力。
“我非常看好中国AI应用的发展前景,如果回顾过去几十年历史,在中国大家都非常愿意拥抱新兴技术。虽然我们没有发明Android、iOS或Windows系统,但我们开发了许多非常创新的应用,比如微信、抖音和滴滴等,还有很多应用都很受欢迎、很实用。在人工智能时代,也是同样的情况。科技带来了很多可能,我们非常善于开发应用,并充分利用了这些可能。”——李彦宏
有人对比Chatgpt4表示遗憾
文心一言的话题风波从未停息过,部分人表示对比GPT4,文心一言的表现在AIGC领域让人并不满意,百度近几月在技术层面的人员变动也让一部分人对百度所说的重做、重构全部产品抱有怀疑态度。
李彦宏曾在文心一言发布会坦言,文心一言不算完美,但市场已经因ChatGPT催生出了焦虑,文心一言对比ChatGPT也的确有差距。文心一言发布会当天,百度股价大幅下跌,市场对百度2017年开始的“AllinAI”也报了怀疑态度。
但,现实是中国缺少大量底层基础的人工智能学科技术研究,“被卡脖子”的先进AI芯片问题依旧没有解决,追上ChatGPT,打出中国的“王炸”AI,一定是一个天方夜谭。
在ChatGPT出现后,全球涌现多个基于其大模型开发的应用公司,中国这边也相继新增一批人工智能相关企业,大部分是基于开源模型研发应用的公司,对外宣称自己是中国的ChatGPT。
应用研发相对底层技术研发要更简单,资金消耗也更小,大部分企业更愿意基于现有模型上研发应用,研究AI的算法,但研发大模型的非常少,因为风险高、收益低,恐怕除了百度这些有实力的大厂,小企业无法在市场上活下去,这也是中国人工智能产业发展缓慢的原因。
百度说要重做、重构所有应用应该不是虚谈,因为时代已经替百度做出了选择,“文心杯”也是百度筛选潜力原生应用(基于文心大模型)的重要途径,就像李彦宏提到的“10年后全世界有50%的工作会是提示词工程”,这大概更倾向于百度提前收集未来的提示词方向,是“文心大模型+想象力”的具象化。
未来,现有应用都会被替换为大模型催生的原生应用,意味着企业未来必须具备控制AI的能力,“文心千帆”有个微调功能,企业可以在平台上基于任何开源与闭源的大模型,开发自己的大模型,是可视化的微调大模型,具备定制性,这意味着企业被赋予了控制AI的能力。
5月31日,百度的创始人李彦宏在摩根大通全球中国峰会上正式启动了”文心杯”创业大赛
需要网络免费
资讯AI更多
资讯AI 更多

西班牙拟立法打击AI生成的色情图像,保护未成年人隐私
更新时间:2025-03-26

吉卜力风格AI图刷屏,OpenAI测试GPT - 4o生图模型水印
更新时间:2025-04-08

快手发布财报:Allin视频大模型可灵AI商业化首战告捷
更新时间:2025-03-27
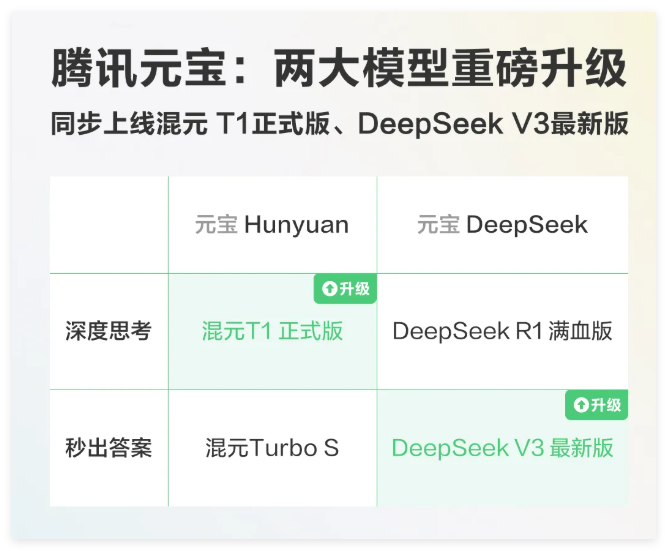
腾讯混元T1正式版和DeepSeekV3-0324上线元宝
更新时间:2025-03-29

互联网医疗AI布局提速,服务质量升级把握新契机
更新时间:2025-04-01

德克萨斯州Alpha学校应用AI辅导系统后,学生成绩提升至全美顶尖行列。
更新时间:2025-04-08
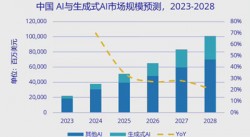
IDC发布报告:全球与中国AI市场投资规模将大幅增长
更新时间:2025-04-08

【重磅来袭】小米MIJIA智能音频眼镜2全新上市,轻薄设计实现录音控车功能,科技升级引领潮流!
更新时间:2025-04-08

全球首款智能体重管理助手“减单”诞生,开启健康新纪元。
更新时间:2025-04-09

Midjourney核心开发者theseriousadult离职,投身Cursor研发AI编程智能体
更新时间:2025-04-10


















