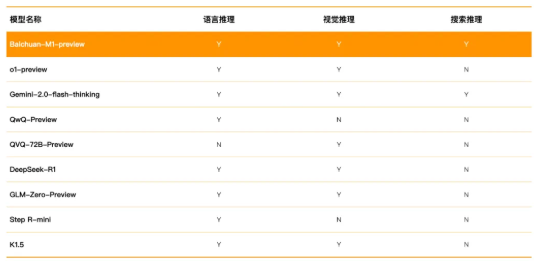
FireRedASR,小红书FireRed 团队发布并开源的基于大模型的语音识别模型,它在中文普通话语音识别领域取得了新的SOTA,FireRedASR支持方言、英语及歌词识别。
大家好~这里是小编!本期【放心AI网-核心AI】带你解锁超实用AI神器,精选全网热门工具,助你一键开启智能新体验!
FireRedASR 是由小红书 FireRed 团队于2025年2月9日发布并开源的基于大模型的语音识别模型,它在中文普通话语音识别领域取得了新的SOTA(字错误率CER 3.05%),并支持方言、英语及歌词识别。
高精度语音识别:FireRedASR-LLM(8.3B参数量)在公开测试集上取得了3.05%的字错误率(CER),成为新的SOTA,相比此前的SOTA模型Seed-ASR(12B+参数)降低了8.4%的错误率。
高效推理:FireRedASR-AED(1.1B参数量)在保持高准确率的同时,显著提升了推理效率,其CER为3.18%。
多场景适配:FireRedASR在短视频、直播、语音输入和智能助手等多种日常场景下表现出色,与业内领先的ASR服务提供商和Paraformer-Large相比,CER相对降低23.7%~40.0%。
歌词识别能力:在需要歌词识别能力的场景中,FireRedASR-LLM的CER实现了50.2%~66.7%的相对降低,展现了极强的适配能力。
多语言支持:FireRedASR支持普通话,在中文方言和英语语音识别方面表现出色,进一步拓宽了其应用范围。

架构:采用Encoder-Adapter-LLM框架,结合大型语言模型Qwen2-7B-Instruct,通过LoRA微调实现端到端语音交互。
性能:在普通话基准测试中CER为3.05%,相比前SOTA模型错误率降低8.4%;歌词识别场景CER相对降低50.2%~66.7%。
特点:参数8.3B,专注极致精度,适合高要求场景如专业字幕生成。
架构:基于注意力编码器-解码器(Conformer编码器+Transformer解码器),参数1.1B。
性能:CER 3.18%,优于12B参数的Seed-ASR,推理效率更高。
特点:平衡准确率与计算效率,适合实时应用如直播字幕、语音助手。
多场景适配:在短视频、直播等日常场景中,CER相对降低23.7%~40.0%;支持中文方言和英语。
开源生态:模型与代码已开源(GitHub),采用工业级设计,支持社区二次开发。
训练策略:LLM版本固定大部分参数,仅训练编码器和适配器,保留预训练能力。
智能语音交互:FireRedASR可以应用于智能语音助手、语音输入法等场景,提供高精度的语音识别服务。
多媒体内容理解:FireRedASR在视频字幕生成、歌词识别等多媒体内容理解场景中表现出色。
日常场景应用:FireRedASR在短视频、直播、语音输入和智能助手等多种日常场景下表现出色,与业内领先的ASR服务提供商和Paraformer-Large相比,CER相对降低23.7%~40.0%。
项目地址:https://github.com/FireRedTeam/FireRedASR
论文地址:https://arxiv.org/abs/2501.14350
今天的AI工具安利就到这里啦!小伙伴们还想看哪些神器?快留言告诉小编,放心AI网-核心AI下期继续带你挖宝!
需要网络免费
资讯AI更多
教程推荐
资讯AI 更多

亚马逊推出全新智能助手Alexa+,语音指令执行餐馆预订等任务
更新时间:2025-04-19
快手可灵AI全面接入DeepSeek-R1,DeepSeek灵感版已上线
更新时间:2025-04-12

OpenAI与CoreWeave达成合作,签订119亿美元合同
更新时间:2025-04-15

NvidiaRTX5070FoundersEdition发布推迟
更新时间:2025-04-17
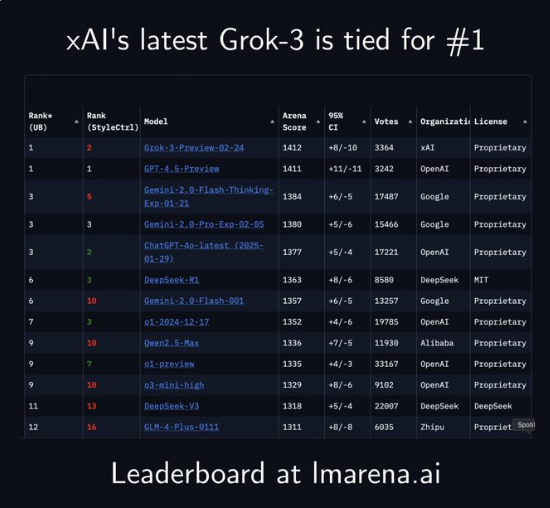
从编码到创意写作xAIGrok-3击败GPT4.5全能登顶大模型竞技场
更新时间:2025-04-18

德国电信携手Perplexity推出AI手机,挑战苹果谷歌生态
更新时间:2025-04-18

AMD发布全新RadeonRX9070系列显卡,性能大幅提升直逼RTX50
更新时间:2025-04-18

Netflix新招机器学习科学家与工程师,推动内容智能化
更新时间:2025-04-18
Perplexity推出5000万美元种子与前种子投资基金
更新时间:2025-04-20
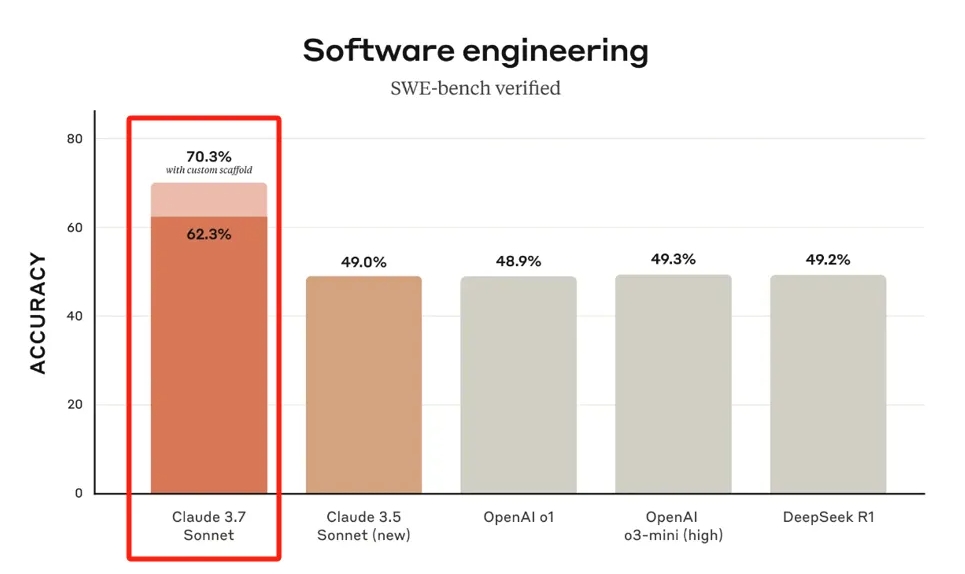
Anthropic推出混合推理模型Claude3.7Sonnet:能力超DeepSeek
更新时间:2025-04-21