JoyGen,京东科技与香港大学合作开发的音频驱动3D说话人脸视频生成框架,提供精确的唇部与音频同步,以精确模拟说话者的唇部动作和面部表情,让生成的视频更逼真。
大家好~这里是小编!本期【放心AI网-核心AI】带你解锁超实用AI神器,精选全网热门工具,助你一键开启智能新体验!
JoyGen 是由京东科技与香港大学合作开发的音频驱动3D说话人脸视频生成框架,一种新颖的两阶段框架,这个技术在于通过音频输入来驱动3D深度感知模型,提供精确的唇部与音频同步,以精确模拟说话者的唇部动作和面部表情,让生成的视频更逼真,主要应用于视频编辑和虚拟交互领域。
JoyGen使用了一个包含130小时高质量视频的中文说话人脸数据集进行训练。这个数据集与开放的HDTF(高分辨率深度图数据集)结合,支持中文和英文输入。
另外,JoyGen也考虑了音频的情绪特征,能够在生成的动画中自然地表现出人物的情感变化,例如微笑或皱眉等,非常的强。
多语言支持:JoyGen能够处理中文和英文等多种语言的音频输入。
高质量视觉效果:通过细致的面部表情和唇部细节处理,生成的视频极其逼真。
精确唇部同步:通过音频特征分析和面部深度图技术,使视频中人物的唇部动作与音频内容完美匹配。
视频编辑优化:不仅生成新视频,还能对现有视频进行唇部运动的编辑,不需要从头开始又制作整个视频序列。
高效技术架构:采用单步UNet架构,可以让视频编辑流程更简单了。
利用3D重建模型从面部图像提取身份特征,定义人物的独特面部结构。
通过音频到运动模型,将音频信号转换为控制唇部运动的表情系数。
结合身份和表情系数,使用可微渲染技术生成面部深度图,为后续视频合成准备。
采用单步UNet网络整合音频特征与深度图,直接生成包含精确唇部运动的视频帧。
引入跨注意力机制,确保唇部运动与音频信号高度一致,增强同步性。
通过优化过程(如L1损失函数)确保视频质量,兼顾像素级和潜在空间的准确性。

环境搭建:用户需创建一个特定的conda环境,并安装必要的依赖包,包括Nvdiffrast等特定库。
预训练模型下载:获取JoyGen的预训练模型,包括3D模型、音频到运动模型等,这些资源通常在项目GitHub页面上提供。
运行推理:通过执行特定的脚本和参数,用户可以将音频文件转换为带有逼真唇部同步的3D说话人脸视频。
虚拟会议:增强虚拟会议中的面部表达。
影视制作:制作电影和电视中的特效。
教育培训:用于制作生动的教育视频。
ai助手:增加Ai助手在人与机器互动中的拟人程度。
JoyGen将复杂的人脸视频生成大大简化了,它在数字人内容创作、虚拟会议、娱乐等地方有非常大的作用。
GitHub:https://github.com/JOY-MM/JoyGen
今天的AI工具安利就到这里啦!小伙伴们还想看哪些神器?快留言告诉小编,放心AI网-核心AI下期继续带你挖宝!
需要网络免费
资讯AI更多
教程推荐
资讯AI 更多

亚马逊推出全新智能助手Alexa+,语音指令执行餐馆预订等任务
更新时间:2025-04-19
快手可灵AI全面接入DeepSeek-R1,DeepSeek灵感版已上线
更新时间:2025-04-12

OpenAI与CoreWeave达成合作,签订119亿美元合同
更新时间:2025-04-15

NvidiaRTX5070FoundersEdition发布推迟
更新时间:2025-04-17
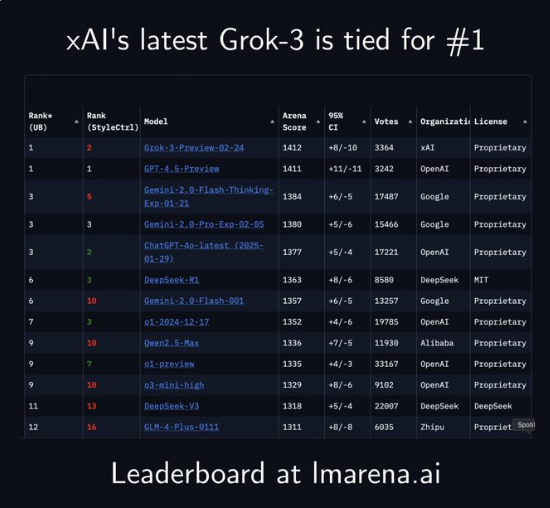
从编码到创意写作xAIGrok-3击败GPT4.5全能登顶大模型竞技场
更新时间:2025-04-18

德国电信携手Perplexity推出AI手机,挑战苹果谷歌生态
更新时间:2025-04-18

AMD发布全新RadeonRX9070系列显卡,性能大幅提升直逼RTX50
更新时间:2025-04-18

Netflix新招机器学习科学家与工程师,推动内容智能化
更新时间:2025-04-18
Perplexity推出5000万美元种子与前种子投资基金
更新时间:2025-04-20
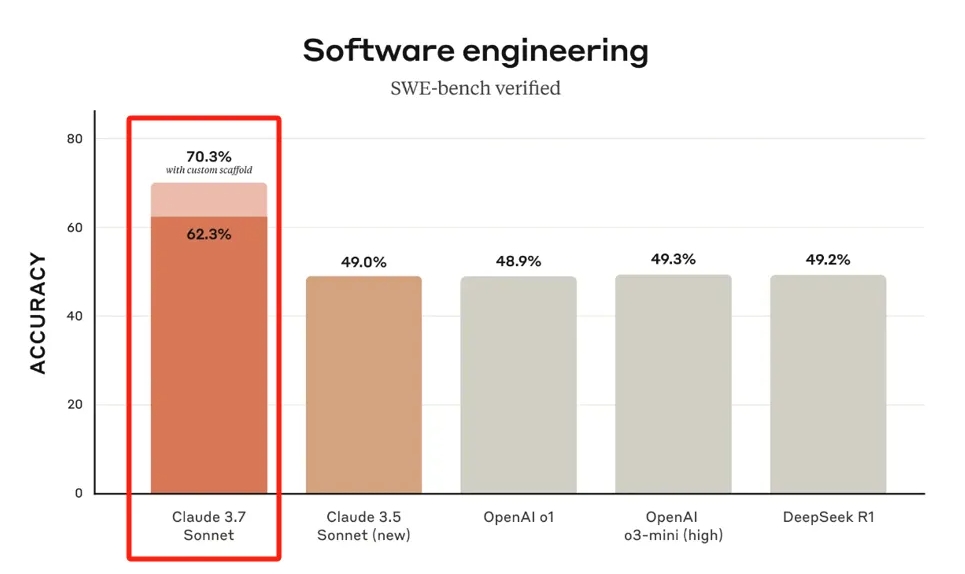
Anthropic推出混合推理模型Claude3.7Sonnet:能力超DeepSeek
更新时间:2025-04-21