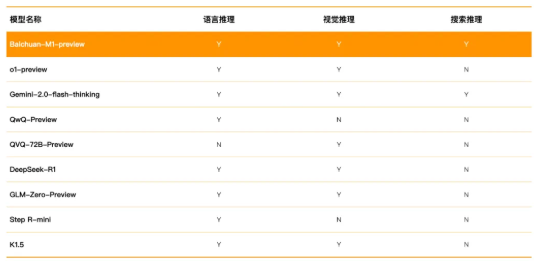
Tarsier,字节跳动推出的一系列大规模视觉语言模型(LVLM),专注于视频理解任务,包括视频描述、问答、视频定位、幻觉测试等功能。
大家好~这里是小编!本期【放心AI网-核心AI】带你解锁超实用AI神器,精选全网热门工具,助你一键开启智能新体验!
Tarsier是字节跳动推出的一系列大规模视觉语言模型(LVLM),专注于视频理解任务,包括视频描述、问答、定位和幻觉测试等功能。

视频描述生成:Tarsier能生成高质量的视频描述,覆盖视频中的各种细节,包括动作、场景和情节,帮助用户更好地理解视频内容。
问答能力:Tarsier模型支持视频问答功能,用户可以基于视频内容提出问题,模型将提供相关的答案。
定位功能:检测并定位视频中特定事件发生的时间,支持多视频段的定位,可以在视频中识别和标记特定对象或场景。
幻觉测试:通过优化训练策略,Tarsier2显著减少了模型生成虚假信息的可能性。
多语言支持:支持多种语言的视频描述生成。
内容创作:Tarsier可以帮助内容创作者生成视频描述,提升视频的可访问性和搜索引擎优化(SEO)效果。
教育领域:在教育视频中,Tarsier可以提供详细的内容描述,帮助学生更好地理解学习材料。
社交媒体:社交平台可以利用Tarsier生成视频内容的自动描述,增强用户体验。
视频监控:在安全监控领域,Tarsier可以分析视频流并生成实时描述,帮助安全人员快速识别潜在威胁。
机器人:为指定任务生成详细的步骤指令。
智能驾驶:帮助车辆识别道路情况,并辅助进行决策。

Tarsier模型的最新版本Tarsier2在多个方面进行了显著的改进,特别是在数据量和多样性方面。预训练数据从1100万扩展到4000万视频文本对,增强了模型的学习能力。此外,Tarsier2在监督微调阶段引入了细粒度时间对齐,进一步提高了视频描述的准确性和细节捕捉能力。通过直接偏好优化(DPO)训练,Tarsier2能够生成更符合人类偏好的视频描述,减少生成幻觉的可能性。
在性能评估方面,Tarsier2在DREAM-1K基准测试中表现出色,其F1分数比GPT-4o高出2.8%,比Gemini-1.5-Pro高出5.8%。在15个公共基准测试中,Tarsier2取得了新的最佳结果,涵盖视频问答、视频定位、幻觉测试和问答等功能,展示了其作为强大通用视觉语言模型的多功能性。

除了视频描述之外,它还在问答、grounding和embodied intelligence等任务中展现出强大的性能。
论文:https://arxiv.org/abs/2501.07888
Code: https://github.com/bytedance/tarsier
Dataset: https://huggingface.co/datasets/omni-research/DREAM-1K
Demo: https://huggingface.co/spaces/omni-research/Tarsier2-7b
今天的AI工具安利就到这里啦!小伙伴们还想看哪些神器?快留言告诉小编,放心AI网-核心AI下期继续带你挖宝!
需要网络免费
资讯AI更多
教程推荐
资讯AI 更多

亚马逊推出全新智能助手Alexa+,语音指令执行餐馆预订等任务
更新时间:2025-04-19
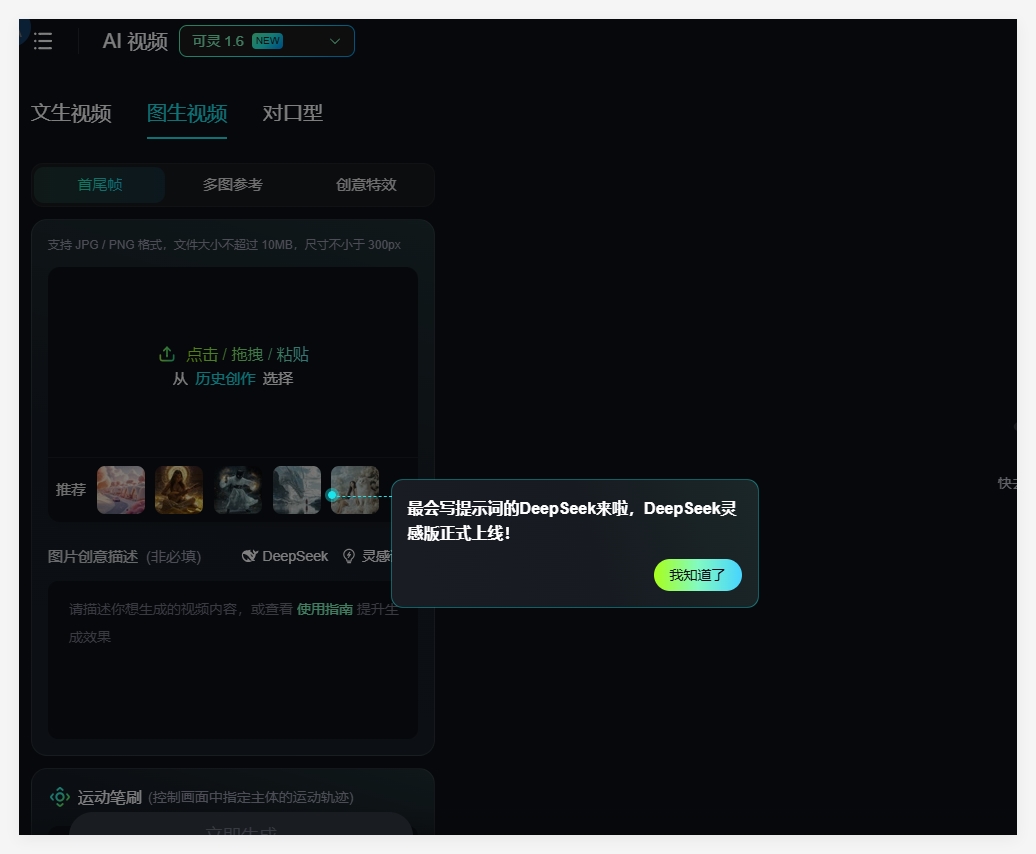
快手可灵AI全面接入DeepSeek-R1,DeepSeek灵感版已上线
更新时间:2025-04-12

OpenAI与CoreWeave达成合作,签订119亿美元合同
更新时间:2025-04-15

NvidiaRTX5070FoundersEdition发布推迟
更新时间:2025-04-17
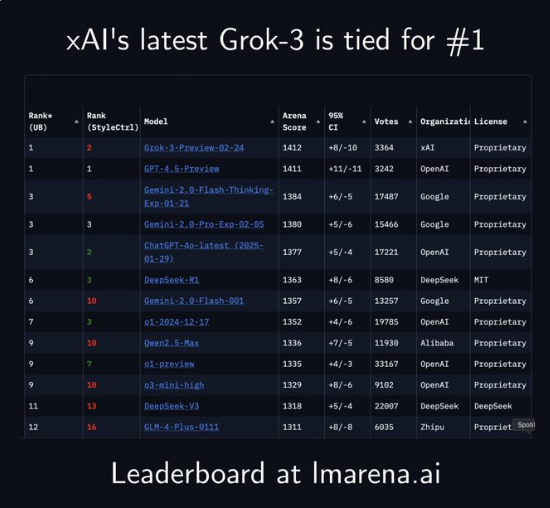
从编码到创意写作xAIGrok-3击败GPT4.5全能登顶大模型竞技场
更新时间:2025-04-18

德国电信携手Perplexity推出AI手机,挑战苹果谷歌生态
更新时间:2025-04-18

AMD发布全新RadeonRX9070系列显卡,性能大幅提升直逼RTX50
更新时间:2025-04-18

Netflix新招机器学习科学家与工程师,推动内容智能化
更新时间:2025-04-18
Perplexity推出5000万美元种子与前种子投资基金
更新时间:2025-04-20
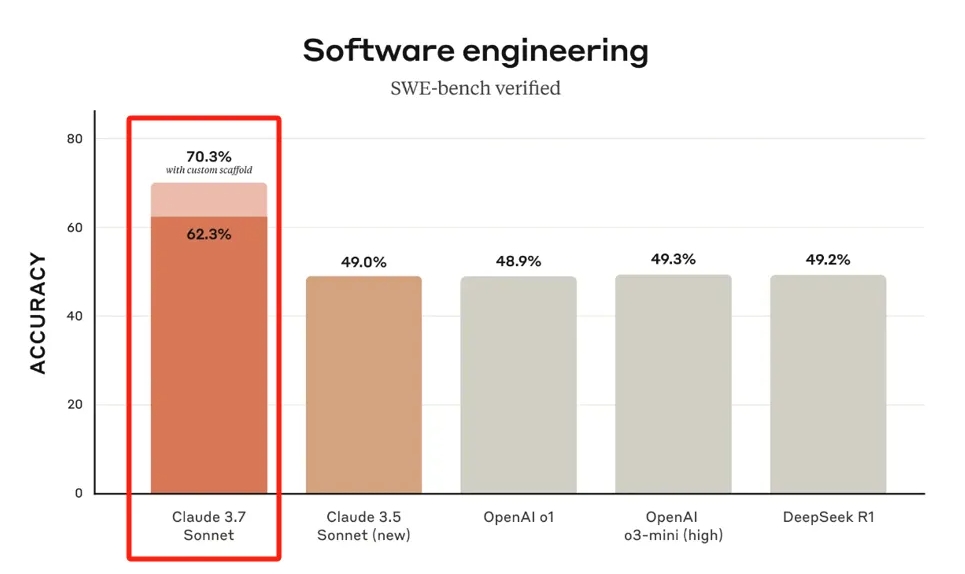
Anthropic推出混合推理模型Claude3.7Sonnet:能力超DeepSeek
更新时间:2025-04-21