Qwen2 5,超大规模语言模型,强大的自然语言处理和多模态交互能力
放心AI网·扩展AI栏目来啦!小编带你挖掘那些小众但超好用的AI神器,错过就亏大啦~
Qwen2.5官网,超大规模语言模型,强大的自然语言处理和多模态交互能力
Qwen2.5是由阿里云通义千问团队开发的超大规模语言模型系列,旨在提供强大的自然语言处理和多模态交互能力。Qwen2.5系列大语言模型,宣称在72项国际权威评测中全面超越国内爆款模型DeepSeek-V3,部分能力甚至比肩GPT-4Turbo。
qwen大模型官网:https://qwen2.org/
qwen大模型
github项目地址:
https://github.com/QwenLM
Qwen2.5是一系列大型语言模型(LLMs),旨在满足多样化的需求。与之前的版本相比,Qwen2.5在预训练和后训练阶段都得到了显著改进。预训练数据集从之前的7万亿个token扩展到18万亿个token,这为模型提供了坚实的常识、专家知识和推理能力基础。后训练阶段包括超过100万个样本的复杂监督微调和多阶段强化学习,显著提升了模型的人类偏好对齐、长文本生成、结构数据分析和指令遵循能力。
Qwen2.5系列特点
丰富的配置:提供从0.5B到72B参数的不同大小的基础模型和指令调整模型,以及量化版本。
性能表现:在多个基准测试中表现出色,特别是在语言理解、推理、数学、编码和人类偏好对齐等方面。
模型规模:Qwen2.5-72B-Instruct在性能上与比它大5倍的Llama-3-405B-Instruct竞争。
架构与分词器 Qwen团队又一次给我们带来了惊喜。这款全新的视觉语言模型,不仅功能全面升级,更是在多个维度上展现了超越以往的实力。 Qwen2.5系列包括基于Transformer的密集模型和用于API服务的MoE(专家混合)模型。模型架构包括分组查询注意力、SwiGLU激活函数、旋转位置嵌入等。分词器使用字节级别的字节对编码(BBPE),词汇量为151,643个常规token。 预训练 预训练数据质量得到显著提升,包括更好的数据过滤、数学和代码数据的整合、合成数据的生成和数据混合。预训练数据从7万亿token增加到18万亿token。 后训练 Qwen2.5在后训练设计上引入了两个重要进展:扩展的监督微调数据覆盖和两阶段强化学习(离线和在线)。 评估 Qwen2.5系列模型在多个基准测试中进行了评估,包括自然语言理解、编程、数学和多语言能力。Qwen2.5-72B和Qwen2.5-Plus在多个任务中表现出色,与领先的开放权重模型竞争。 basemodel instructmodel onourin-houseChineseautomaticevaluation 长文本 结论 Qwen2.5代表了大型语言模型的重大进步,提供了多种配置,并且在多个基准测试中表现出色。Qwen2.5的强大性能、灵活架构和广泛可用性使其成为学术研究和工业应用的宝贵资源。 以下是关于Qwen2.5的详细简介: 架构:Qwen2.5基于MixtureofExperts(MoE)架构,通过智能选择适当的“专家”模型来优化计算资源,提高推理速度和效率。 规模:Qwen2.5系列包括多个不同规模的版本,如Qwen2.5-7B、Qwen2.5-14B、Qwen2.5-32B和Qwen2.5-72B。其中,Qwen2.5-Max是旗舰版本,采用超过20万亿tokens的预训练数据。 多模态交互:Qwen2.5-VL版本支持视觉语言多模态任务,能够识别和分析图像、视频中的文本、图表、图标和布局。它还支持长视频理解,能够处理超过1小时的视频内容。 编程辅助:Qwen2.5-Coder版本支持多达40多种编程语言,能够生成高质量的代码、进行代码优化和调试。 数学推理:Qwen2.5-Math版本支持中英双语,整合了多种推理方法,包括思维链、程序推理和工具集成推理。 长文本处理:支持高达128Ktokens的上下文长度,并能生成最多8Ktokens的内容。 多语言支持:支持包括中文、英文、法文、西班牙文等在内的29种以上语言。 结构化数据处理:能够高效解析发票、表格、文档等结构化数据,并生成准确的结构化输出。 基准测试:Qwen2.5在多个基准测试中表现出色,包括MMLU-Pro(测试大学水平知识)、LiveCodeBench(评估编程能力)、LiveBench(全面评估综合能力)和Arena-Hard(近似人类偏好)。 性能对比:在Arena-Hard、LiveBench、LiveCodeBench和GPQA-Diamond等基准测试中,Qwen2.5-Max的表现领先。它还在MMLU-Pro等其他评估中展现出极具竞争力的成绩。 与国际领先模型对比:Qwen2.5-Max在多项测试中超越了DeepSeekV3、GPT-4o和Claude-3.5-Sonnet等国际领先模型。 教育领域:作为智能辅导工具,帮助学生理解复杂知识概念,辅助写作、数学解题等。 企业办公:用于智能客服、自动化办公,如撰写报告、整理数据等。 科研领域:支持文献综述、实验设计等科研任务。 编程开发:为开发者提供代码生成、优化和调试辅助,加快软件开发进程。 开源许可:Qwen2.5系列模型大多采用Apache2.0许可证,方便开发者进行本地部署和微调。 部署平台:用户可以通过QwenChat平台直接体验,或者通过阿里云百炼平台调用API服务。 通义千问团队表示,将持续提升数据规模和模型参数规模,以进一步增强模型的智能水平。此外,团队还将大力投入强化学习的scaling,目标是实现超越人类的智能,推动AI探索未知领域。 Qwen2.5凭借其强大的多模态交互能力、多语言支持和专业领域的优化,展现出广泛的应用前景和巨大的潜力。它不仅在多个基准测试中超越了当前领先的模型,还支持灵活的定制化应用,广泛适用于企业和开发者。 Qwen2.5系列大语言模型在国际权威评测中取得了显著成绩,全面超越了国内热门模型DeepSeek-V3,部分能力甚至接近GPT-4Turbo。这一成就不仅在科技界引起了广泛关注,也在安全领域引发了深度思考:随着国产大模型的快速迭代,其背后的技术进步是否隐藏着安全风险?这场AI竞赛又将如何重塑全球技术格局? 一、Qwen2.5的技术突破:从“追赶者”到“领跑者”的跨越 技术解析:中国大模型的“超车密码” 参数规模的“三级跳” 基础版Qwen2.5的参数规模突破了3000亿,相较于前代Qwen2的1100亿有了显著提升。该模型采用了创新的“混合专家”(MoE)架构,推理效率提高了40%。 多模态版本整合了视觉、语音和文本三种模态,单次输入支持百万token级上下文,相当于一部《三体》全集的规模。 性能指标的“碾压式领先” 在中文理解任务中,Qwen2.5以87.3分的成绩超越了DeepSeek-V3的83.5分(基于CEVAL基准)。 在代码生成能力方面,Qwen2.5达到了HumanEval76.8%的准确率,而DeepSeek-V3为72.1%,接近GPT-4的81.7%。 杀手级应用场景 网络安全攻防推演:Qwen2.5能够模拟APT攻击链,并自动生成防御策略方案。阿里内部测试显示,攻击路径预测准确率高达91%。 漏洞自动化挖掘:通过代码语义分析,Qwen2.5发现逻辑漏洞的效率提升了3倍。 二、技术跃进背后的“暗战”:中国AI的竞合博弈 行业观察:大模型赛道的“三国杀” DeepSeek-V3的“反制武器” 据知情人士透露,深度求索(DeepSeek)正在秘密研发V3Pro版本,主打“轻量化部署”。该版本将模型压缩至70亿参数,推理速度提升200%,主要针对企业级安全场景。 BAT的“军备竞赛” 百度文心大模型4.0:已启动多轮安全压力测试,重点防范“模型越狱”攻击。 腾讯混元大模型:强化了金融风控能力,能够实时检测交易欺诈模式。 国际赛场的新变量 美国AI公司Anthropic的最新研究显示,中国大模型在中文语料覆盖度上已达到GPT-4的92%,但在多语言泛化能力上仍有差距。 三、安全界的“灵魂拷问”:大模型是盾牌还是漏洞? 深度剖析:AI赋能的“双刃剑效应” 攻击面扩张:新型威胁浮出水面 Prompt注入风险:黑客可能通过精心构造的指令,诱使大模型泄露训练数据。例如,某金融公司测试发现,Qwen2.5在连续诱导下可能输出敏感字段。 自动化社工攻击:基于大模型的钓鱼邮件生成效率提升了10倍,语言逼真度突破了人类识别阈值。 防御革命:AI驱动的安全范式 智能威胁狩猎:Qwen2.5能够实时分析10TB级日志数据,将APT攻击检出时间从72小时缩短至15分钟。 漏洞优先级研判:通过CVSS评分和上下文语义分析,误报率降低了60%。 伦理与合规的“灰色地带” 训练数据版权争议:Qwen2.5被指使用了未授权的开源代码库。 模型输出不可控性:测试显示,在极端场景下,Qwen2.5可能会生成高危渗透测试指令。 四、未来已来:大模型时代的攻防战略 趋势预测:安全从业者的生存指南 技术层面 建立“AI防火墙”:开发针对大模型输入输出的动态过滤系统,例如OpenAI的ModerationAPI。 推行“零信任AI”:对模型行为实施细粒度权限控制,参考MITRE新发布的ATT&CKforAI框架。 管理层面 制定《大模型安全应用白名单》:禁止在关键基础设施中使用未认证模型。 建立AI安全“红蓝对抗”机制:定期进行攻防演练,阿里云已推出AI安全靶场服务。 人才层面 培养“AI安全工程师”复合型人才:需同时掌握机器学习与渗透测试技能。 开发自动化审计工具:降低大模型运维门槛,例如FiddlerAI推出的模型监控平台。 Qwen2.5系列大语言模型的突破不仅展示了中国在AI领域的技术实力,也引发了对安全和伦理问题的深入思考。随着技术的不断进步,如何在享受AI带来的便利的同时,有效应对潜在的风险,将是未来的重要课题。 以上就是放心AI网扩展AI栏目的全部推荐!这些隐藏好货,小编下次继续帮你淘!1.模型架构与规模
2.功能特性
3.性能表现
4.应用场景
5.开源与部署
6.团队展望
总结
qwen2.5测评
Qwen2.5系列大语言模型的突破与挑战
需要网络免费
资讯AI更多
资讯AI 更多

西班牙拟立法打击AI生成的色情图像,保护未成年人隐私
更新时间:2025-03-26

吉卜力风格AI图刷屏,OpenAI测试GPT - 4o生图模型水印
更新时间:2025-04-08

快手发布财报:Allin视频大模型可灵AI商业化首战告捷
更新时间:2025-03-27
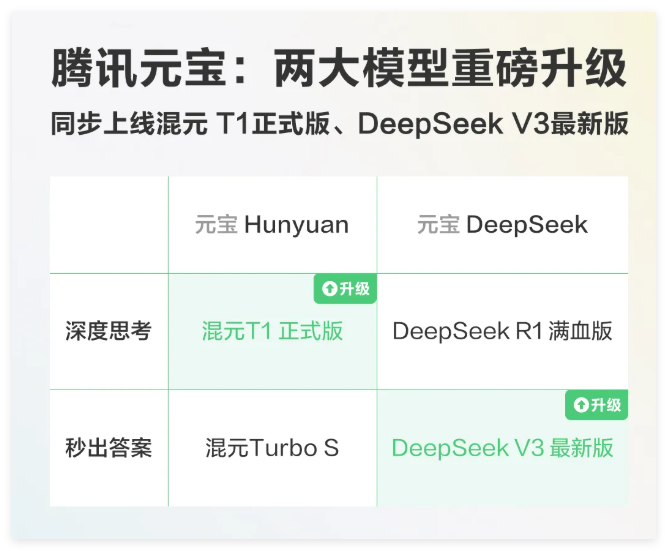
腾讯混元T1正式版和DeepSeekV3-0324上线元宝
更新时间:2025-03-29

互联网医疗AI布局提速,服务质量升级把握新契机
更新时间:2025-04-01

德克萨斯州Alpha学校应用AI辅导系统后,学生成绩提升至全美顶尖行列。
更新时间:2025-04-08
IDC发布报告:全球与中国AI市场投资规模将大幅增长
更新时间:2025-04-08

【重磅来袭】小米MIJIA智能音频眼镜2全新上市,轻薄设计实现录音控车功能,科技升级引领潮流!
更新时间:2025-04-08

全球首款智能体重管理助手“减单”诞生,开启健康新纪元。
更新时间:2025-04-09

Midjourney核心开发者theseriousadult离职,投身Cursor研发AI编程智能体
更新时间:2025-04-10



















