Qwen2-VL ,阿里通义千问开源视觉语言模型
放心AI网·扩展AI栏目来啦!小编带你挖掘那些小众但超好用的AI神器,错过就亏大啦~
Qwen2-VL官网,阿里通义千问开源视觉语言模型
Qwen2-VL是阿里巴巴达摩院开源的最新一代视觉语言模型,它在图像和视频理解任务上取得了显著的成绩,甚至在多个指标上超过了GPT-4o等闭源模型。
项目官网:https://qwenlm.github.io/zh/blog/qwen2-vl/
GitHub仓库:https://github.com/QwenLM/Qwen2-VL
HuggingFace模型库:https://huggingface.co/collections/Qwen/qwen2-vl
体验Demo:https://huggingface.co/spaces/Qwen/Qwen2-VL
api服务:https://help.aliyun.com/zh/model-studio/developer-reference/qwen-vl-api
Qwen2-VL具备以下特点:
1.多分辨率图像理解:Qwen2-VL能够读懂不同分辨率和不同长宽比的图片,在视觉理解基准测试中取得了全球领先的表现。
2.长视频内容理解:模型能够理解长达20分钟以上的长视频,支持基于视频的问答、对话和内容创作等应用。
3.多语言支持:除了英语和中文,Qwen2-VL还支持理解图像中的多语言文本,包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。
4.动态分辨率支持:Qwen2-VL能够处理任意分辨率的图像输入,无需将图像分割成块,更接近人类视觉感知。
5.多模态旋转位置嵌入(M-ROPE):Qwen2-VL通过创新的位置编码技术,能够同时捕捉和整合一维文本序列、二维视觉图像以及三维视频的位置信息。
Qwen2-VL提供了不同规模的模型,包括2B、7B和72B参数的版本,其中2B和7B版本已可下载并免费商用(Apache2.0),72B则通过API提供。开源代码已集成到HuggingFaceTransformers、vLLM等第三方框架中,便于开发者使用和集成。
Qwen2-VL的应用场景广泛,包括但不限于内容创作、教育辅助、多语言翻译与理解、智能客服、图像和视频分析、辅助设计、自动化测试、数据检索与信息管理、辅助驾驶和机器人导航、医疗影像分析等。
Qwen2-VL的发布标志着开源多模态模型领域的一个重要进展,为AI视觉理解和内容生成领域带来了新的可能性。
Qwen2-VL的主要特性包括:
1.多分辨率图像理解:能够处理不同分辨率和长宽比的图片,适用于多种视觉理解任务。
2.长视频内容理解:能够理解长达20分钟以上的视频内容,支持视频问答和内容创作。
3.多语言支持:支持多种语言的文本理解,包括中文、英文、日文、韩文等。
4.动态分辨率支持:无需将图像分割,能够处理任意分辨率的图像输入。
5.多模态旋转位置嵌入(M-ROPE):能够同时捕捉和整合文本、视觉和视频位置信息。
6.模型规模多样性:提供2B、7B、72B三种规模的模型,以适应不同的应用需求和资源限制。
7.开源和API支持:模型代码开源,提供API接口,便于开发者集成和使用。
Qwen2-VL的应用场景包括:
1.内容创作:自动生成视频和图像内容的描述,辅助多媒体作品的创作。
2.教育辅助:解析数学问题和逻辑图表,提供解题指导。
3.多语言翻译与理解:识别和翻译多语言文本,促进跨语言交流。
4.智能客服:提供即时的客户咨询服务,通过实时聊天功能进行交互。
5.图像和视频分析:在安全监控和社交媒体管理中分析视觉内容,识别关键信息。
6.辅助设计:帮助设计师获取设计灵感和概念图。
7.自动化测试:在软件开发中自动检测界面和功能问题。
8.数据检索与信息管理:通过视觉代理能力提高信息检索和管理的自动化水平。
9.辅助驾驶和机器人导航:作为视觉感知组件,辅助自动驾驶和机器人理解环境。
10.医疗影像分析:辅助医疗专业人员分析医学影像,提升诊断效率。
Qwen2-VL的这些特性和应用场景使其成为一个多才多艺的工具,能够在多个领域内提供强大的视觉和语言处理能力。
以上就是放心AI网扩展AI栏目的全部推荐!这些隐藏好货,小编下次继续帮你淘!
需要网络免费
资讯AI更多
资讯AI 更多

西班牙拟立法打击AI生成的色情图像,保护未成年人隐私
更新时间:2025-03-26

吉卜力风格AI图刷屏,OpenAI测试GPT - 4o生图模型水印
更新时间:2025-04-08

快手发布财报:Allin视频大模型可灵AI商业化首战告捷
更新时间:2025-03-27
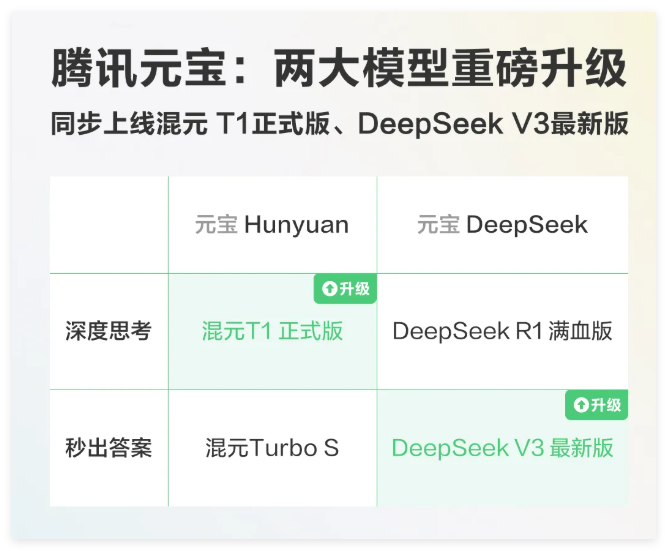
腾讯混元T1正式版和DeepSeekV3-0324上线元宝
更新时间:2025-03-29

互联网医疗AI布局提速,服务质量升级把握新契机
更新时间:2025-04-01

德克萨斯州Alpha学校应用AI辅导系统后,学生成绩提升至全美顶尖行列。
更新时间:2025-04-08
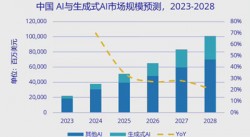
IDC发布报告:全球与中国AI市场投资规模将大幅增长
更新时间:2025-04-08

【重磅来袭】小米MIJIA智能音频眼镜2全新上市,轻薄设计实现录音控车功能,科技升级引领潮流!
更新时间:2025-04-08

全球首款智能体重管理助手“减单”诞生,开启健康新纪元。
更新时间:2025-04-09

Midjourney核心开发者theseriousadult离职,投身Cursor研发AI编程智能体
更新时间:2025-04-10



















